
紙の書類をスキャンしてPDFで保存したはいいものの、あとから「この書類に“契約書”って書いてあったはずだけど、どのページだったかな?」と探し回った経験はありませんか?PDFのスキャンは一見便利ですが、画像データのままだとキーワード検索もコピー&ペーストもできず、探したい情報にたどり着くまで思いのほか時間がかかります。
そこで活躍するのがOCR(光学文字認識)。OCRをかければ画像化された文字をデータとして抽出でき、PDF内検索やテキストコピーが一気に快適になります。しかも、最近はインストール不要で使える無料のオンラインOCRツールが充実しており、初心者でも数クリックで「検索可能なPDF」を作成できます。
本記事では、難しい専門知識なしで試せる無料ツールをピックアップし、Windows/Mac共通の最短ステップで「スキャンPDF→検索可能PDF」へ変換する手順をわかりやすく紹介します。
無料で使えるOCRツールの選び方ポイント
OCR機能自体はAdobeAcrobatなど有料ソフトにも搭載されていますが、無料で使えるツールでも十分実用可能です。特に初心者の方には、以下のポイントでツールを選ぶと良いでしょう:

- 無料で使えること:
追加費用なしでOCRを試せるものを選びます。例えばGoogleドライブのOCR機能は、Googleアカウントがあれば無料で利用可能です。 - 日本語に対応していること:
OCRは言語対応が重要です。日本語の文書を扱うなら日本語認識可能なツールを選びましょう(縦書きに対応しているとなお良いです)。 - Windows/Mac問わず使えること:
パソコンのOSに依存せず利用できるオンラインツールやクロスプラットフォーム対応のソフトがおすすめです。インストール不要のオンラインOCRツールなら、WindowsでもMacでも同じ手順で使えます。 - 操作が簡単なこと:
初心者には直感的に使えるシンプルなUIのものが安心です。ドラッグ&ドロップでファイルを投入するだけなど、手順が少ないものを選びましょう。
以上を踏まえ、初心者でも扱いやすい無料OCRツールを使った具体的な手順を次章で紹介します。
無料オンラインOCRツールでPDFを検索可能にする方法
ここでは、インストール不要で誰でも使えるオンラインOCRツールを使った方法を紹介します。数ある無料OCRサービスの中でも、例えばPDF24Toolsの「PDFOCR」機能は、日本語を含む多言語に対応し(縦書きの日本語もOK)、完全無料でページ数や回数の制限もありません。使い方も非常に簡単です。以下に基本的な手順をまとめます。
オンラインOCRによるPDF文字認識の手順(例:PDF24Tools)
- OCRツールのページにアクセス:ウェブブラウザでOCRツール(例:PDF24ToolsのOCRページ)を開きます。画面上にファイルのアップロード欄が表示されます。
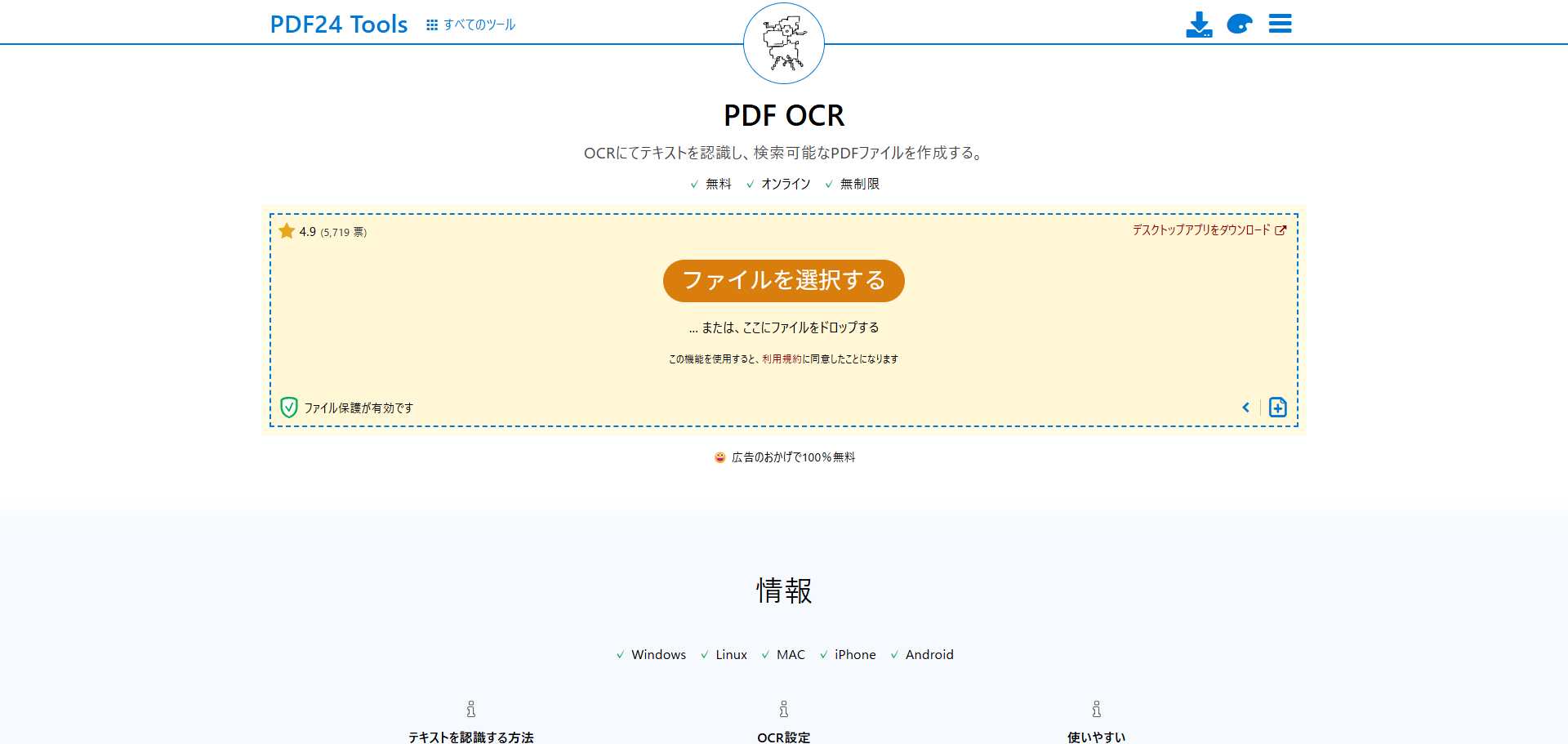
- ファイルをアップロード:OCR処理したいスキャンPDFファイルをドラッグ&ドロップするか、「ファイルを選択」ボタンからアップロードします。複数ページのPDFでもそのまま追加可能です。
- 言語と設定を選択:認識させる言語を日本語に指定します(必要に応じて「Japanese」を選択)。※ツールによっては自動検出の場合もありますが、日本語文書なら明示的に日本語を選ぶと精度が上がります。PDF24Toolsの場合、出力形式は既定でPDF(テキスト付き)になっています。特別な設定変更は不要ですが、必要に応じて「OCR設定」でページの傾き補正やノイズ除去などオプションを調整できます。
- OCR処理の実行:「OCR開始」ボタンをクリックすると処理が始まります。処理時間はPDFのページ数や画像の解像度によりますが、数ページの文書であれば数十秒程度で完了することが多いです。
結果のダウンロード:OCR処理が完了すると、テキスト情報が埋め込まれた新しいPDFファイルが生成されます。画面の指示に従って「ダウンロード」ボタンを押し、検索可能なPDFを保存しましょう。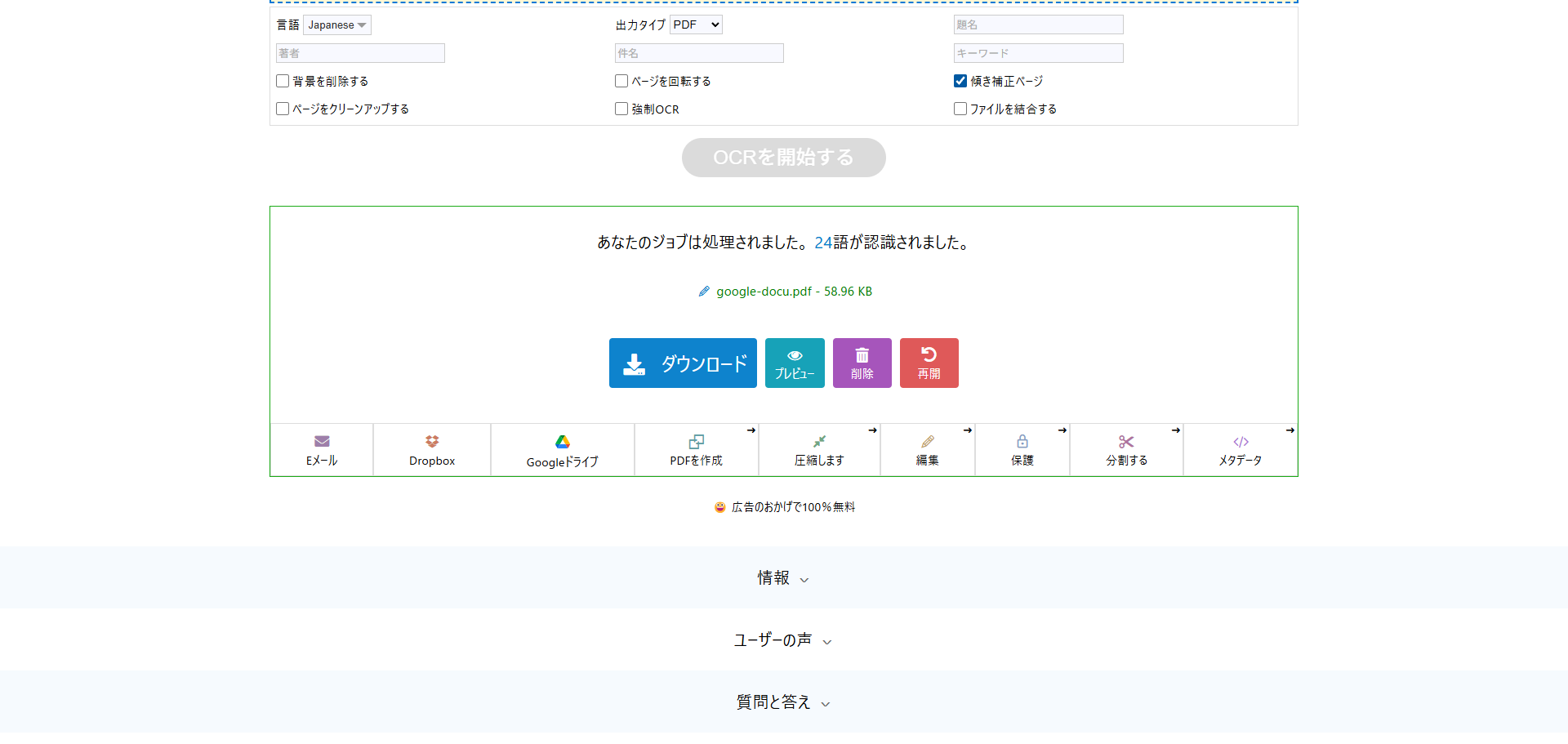
以上でスキャンPDFのOCR処理は完了です。作成されたPDFを開いて文字列を検索したり(Ctrl+F/Cmd+Fでキーワード検索)、コピー&ペーストしてみてください。画像だった文字がちゃんと選択・コピーできるようになっていれば成功です。例えばスマホで撮影した領収書の画像PDFでも、この方法で文字を検索可能なPDFに変換してテキスト内容をコピーできます。
その他の無料OCR活用法(代替ツール紹介)
上記ではオンラインOCRの一例を紹介しましたが、他にも無料でOCRを利用できる方法があります。用途に応じて使いやすい方法を選びましょう。
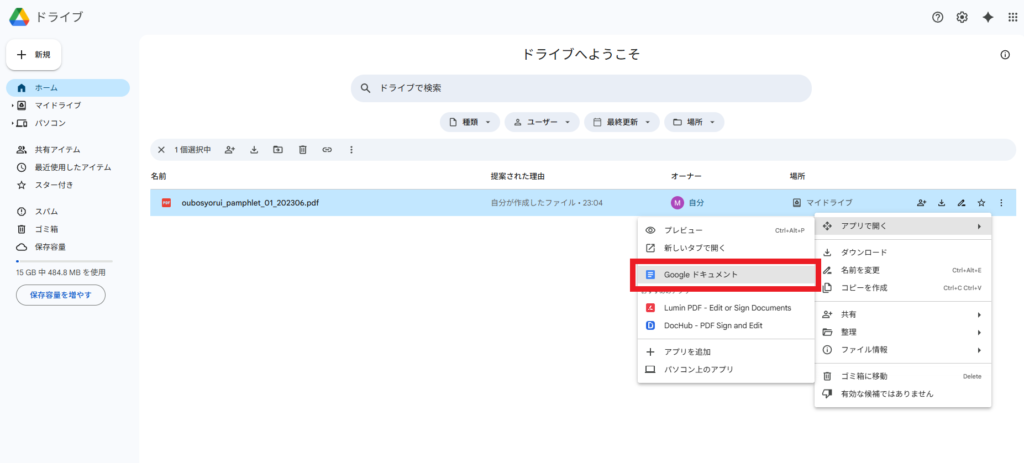
GoogleドライブのOCR機能
実は身近なGoogleドライブでもOCRが可能です。方法は簡単で、GoogleドライブにスキャンPDF(または画像)をアップロードし、それを右クリックして「アプリで開く」→「Googleドキュメント」とするだけです。
自動的に画像内の文字を読み取って、Googleドキュメント上にテキストが抽出されます。無料のGoogleサービスなので追加コストは不要ですし、漢字の認識精度も高く日本語の縦書き文書にも対応しています。抽出結果は編集可能なテキストになるため、そのまま内容を編集したり、必要に応じて「ファイル→ダウンロード」からPDFやWord形式で保存できます。ただしレイアウトは元のPDFと大きく異なる(テキストのみのシンプルな状態)ため、元の紙面レイアウトを保持した検索可能PDFが欲しい場合はオンラインOCRツールの方がおすすめです。
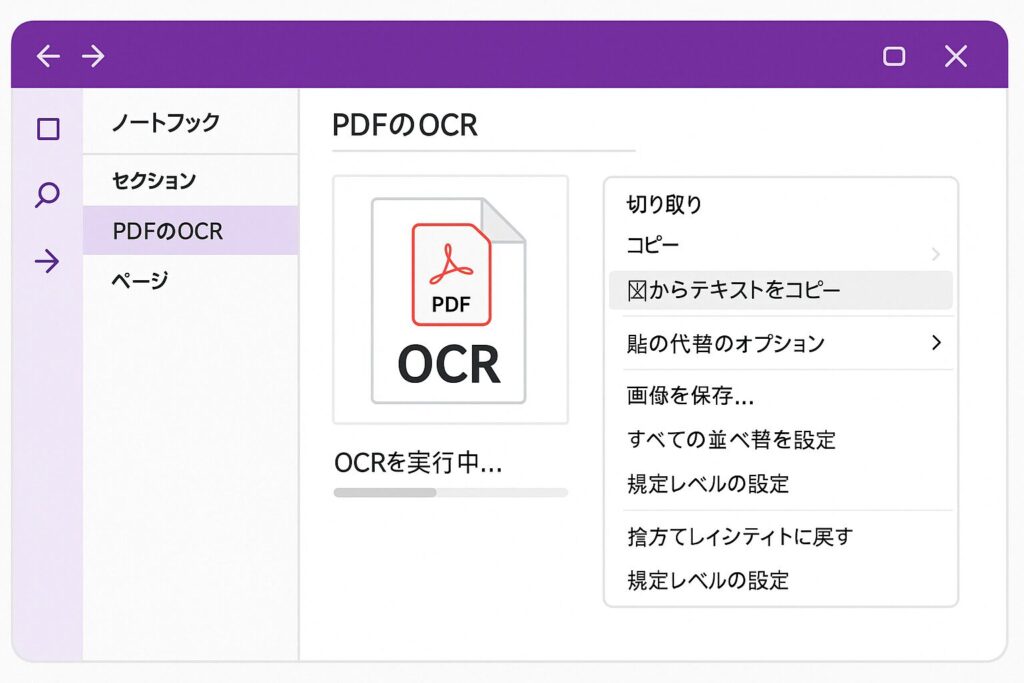
デスクトップ用の無料OCRソフト
Microsoftが提供するOneNoteには画像から文字を抽出するOCR機能が標準搭載されています。PDFをOneNoteに貼り付けて文字起こしするといった使い方も可能です。また、フリーのOCRソフトウェアとしてはReneePDFAide(Windows版あり)やCapture2Text(選択範囲のテキスト抽出ツール)なども知られています。こうしたソフトは一度インストールすればオフラインで利用でき、大量のファイル処理にも適しています。ただし対応OSや操作性の点で初心者にはややハードルが高い場合もあるため、特別な理由がなければ手軽なオンラインサービスやGoogleドライブから試してみると良いでしょう。
まとめ:簡単・無料でPDFを有効活用しよう
スキャンしたPDFを検索可能なPDFに変換することで、資料管理や情報検索が格段に便利になります。無料OCRツールを使えば、初心者でも費用をかけず手軽にOCR処理を実現可能です。本記事で紹介した方法を活用して、ぜひ溜まったスキャン書類をデジタル整理してみてください。
最後に、OCR以外のPDF作業もまとめて効率化したい方には楽々PDFメーカーもおすすめです。楽々PDFメーカー(らくらくPDFメーカー)は安心の国産オンラインPDFツールで、PDFの結合・分割・圧縮やOffice文書からPDFへの変換などが完全に無料で利用できます。
インストール不要・ブラウザ上で動作するためWindows/Mac問わず使え、直感的な操作でPDFを編集・最適化可能です。日々のPDF活用シーンで役立つ便利な機能が揃っていますので、興味のある方はぜひ一度公式サイト()を覗いてみてください。無料ツールを上手に活用して、PDF作業の手間をらくにしましょう!








