
紙の書類をスマホで撮って画像のまま保存していませんか? その画像を無料ツールだけで文字データに起こし、検索や編集ができるPDFに変換できたら、とても便利ですよね。
本記事では、画像から文字を読み取る OCR(光学文字認識) のしくみとメリットを分かりやすく解説しながら、初心者でも今すぐ試せる無料サービスとアプリを手順付きで紹介します。
最後に、OCR済みPDFを仕事や学習にどう活かせるかのアイデアもまとめました。これから「画像→文字→PDF」の流れをマスターして、紙の情報をスマートにデジタル活用しましょう。
OCRの基本
OCR(画像から文字起こし)とは?
OCR(光学式文字認識)とは、画像に含まれる文字をコンピューターが読み取り、テキストデータに変換する技術です。
例えば、紙の書類をスキャンしてできた画像(JPEGやPNG、スキャンPDFなど)やスマホで撮影した書類の写真から、OCRを使って文字情報を抽出できます。抽出された文字データは編集や検索が可能になり、そのまま文章として扱えるようになります。
簡単に言うと、画像の中の「文字」をデータ化する作業がOCRです。これを活用すれば、元は画像だった情報もテキストとしてパソコンやスマホで扱えるようになるため、後述するように様々なメリットがあります。
画像から文字を起こしてPDF化するメリット
画像データ上の文字をテキストに変換し、PDF形式で保存すると次のような利点があります。
- 検索が可能に: OCR後のPDFは文字情報を含むため、キーワードで内容を検索できます。大量の書類の中から必要な情報を素早く見つけられます。
- 編集やコピーが簡単: テキスト化されたPDFなら、一部の文章をコピー&ペーストしたり、誤字を修正したりといった編集が可能です。画像のままではできなかった内容の修正や引用も楽々できます。
- 保存の利便性: テキストPDFは画像ファイルよりも容量が小さくなる場合が多く、メール添付やクラウド保存もしやすくなります。また、テキスト情報を含むPDFはPCやクラウド上で全文検索できるため、後で探し出すのも容易です。
- 活用範囲が広がる: テキストデータになれば翻訳ソフトにかけたり、資料を再編集したり、スクリーンリーダーで読み上げさせたりといった二次利用ができます。紙の書類をそのままデータ活用できるようになる点で、業務効率や学習効率も向上します。
このように、OCRで文字起こしをしてPDF化しておくと、ただ画像を保存するよりも後々の扱いやすさが格段にアップします。
無料で使えるOCRツール・サービスの紹介
それでは、実際に無料で利用できるOCRツールやサービスを使って画像から文字を起こし、PDF化する方法を見ていきましょう。ここでは初心者でも簡単に使える代表的な方法をいくつか紹介します。それぞれ手順を番号付きで説明するので、順番に試してみてください。
方法1: Googleドライブ(Googleドキュメント)のOCR機能を使う

Googleアカウントをお持ちなら、追加のソフトをインストールせずにGoogleドライブ上でOCRを利用できます。Googleドライブに画像やPDFをアップロードし、Googleドキュメントで開くことで自動的に文字起こしが行われます。日本語にも対応しており、精度も比較的高いです。手順は次の通りです。
- Googleドライブにアクセスして画像ファイル(JPEGやPNG)またはスキャンPDFをアップロードします。ドラッグ&ドロップで放り込むか、「新規」ボタンからファイルを選択してアップロードできます。
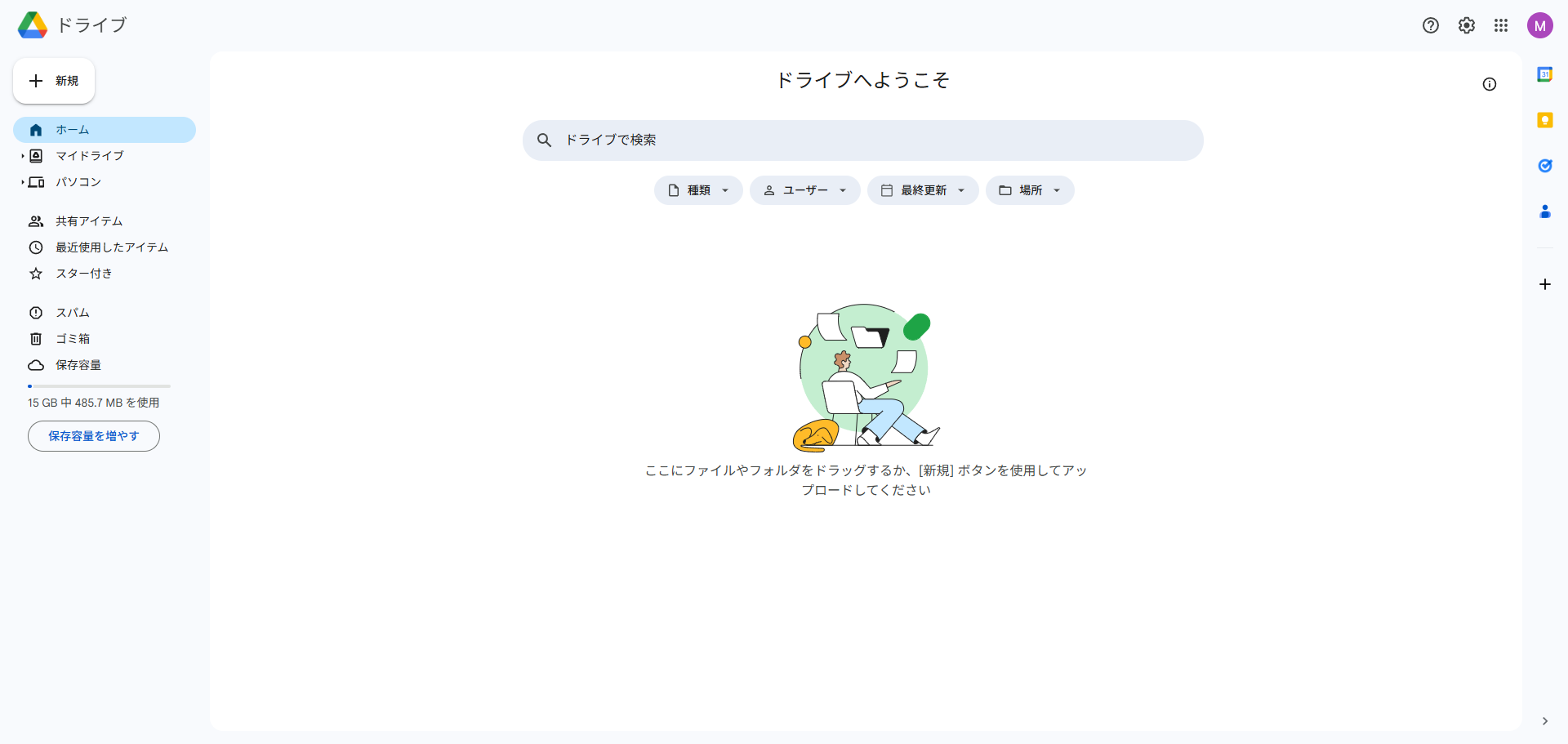
- アップロードしたファイルを右クリックし、表示されるメニューから「アプリで開く」>「Googleドキュメント」を選択します。
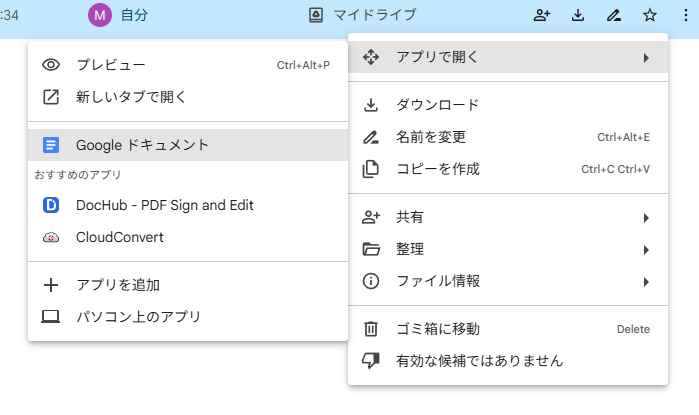
- Googleドキュメントが立ち上がり、しばらく待つと画像内の文字がテキストに変換された状態で表示されます。元画像もドキュメント内に挿入され、その下に抽出されたテキストが書き出される形です。
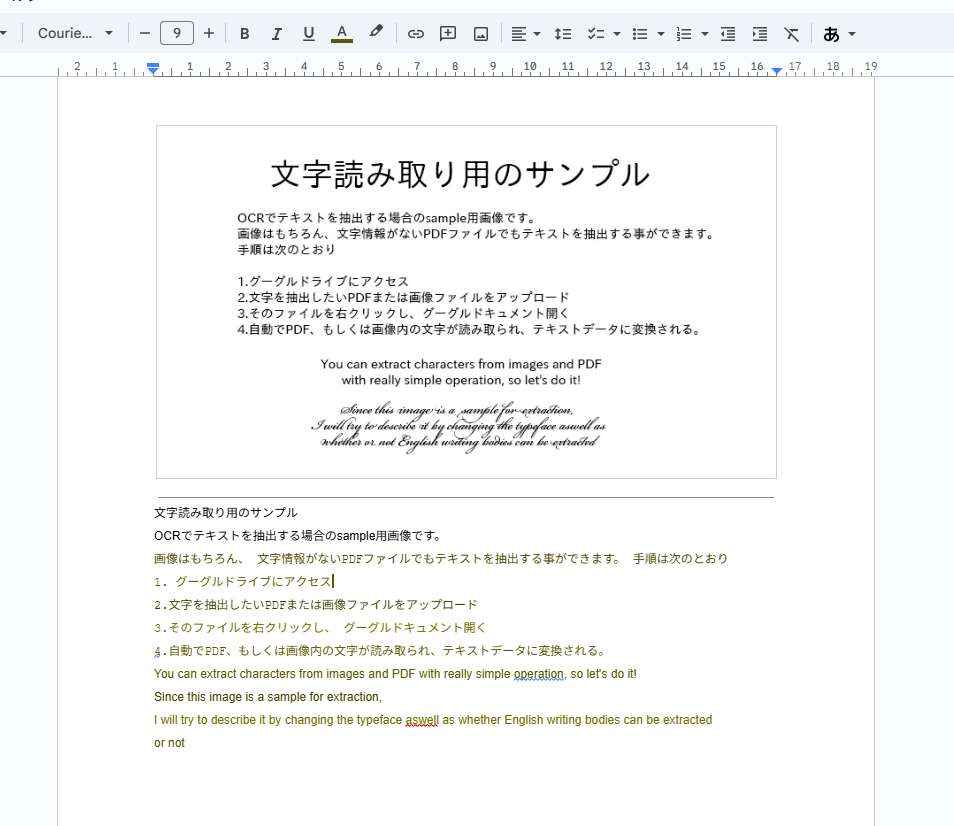
- 抽出されたテキストに誤認識がないか確認し、必要に応じてテキストを編集・修正します。段落の区切りや記号など、OCR結果を整えるとよいでしょう。
- テキスト化が完了したら、メニューから「ファイル」>「ダウンロード」>「PDFドキュメント(.pdf)」を選択します。これで、編集したテキスト内容がPDFファイルとしてダウンロードされます。
方法2: オンラインの無料OCRサイトを利用する(例:OCR.Space)

インストール不要で使えるオンラインOCRサービスも多数存在します。ウェブサイト上に画像やPDFをアップロードすると、その場で文字を読み取って結果を返してくれる便利なサービスです。その中でも OCR.Space というサイトは登録不要・完全無料で使え、日本語を含む多言語のOCRに対応しています。使い方の一例を紹介します。

- ウェブブラウザで OCR.Space のサイト(無料オンラインOCRページ)にアクセスします。
- ページ内の「ファイルをアップロード」の欄にある「ファイルを選択」ボタンをクリックし、OCRしたい画像ファイルもしくはPDFファイルを選んでアップロードします。複数の画像を一度に処理したい場合は、事前に後述の方法で1つのPDFにまとめておくと便利です。
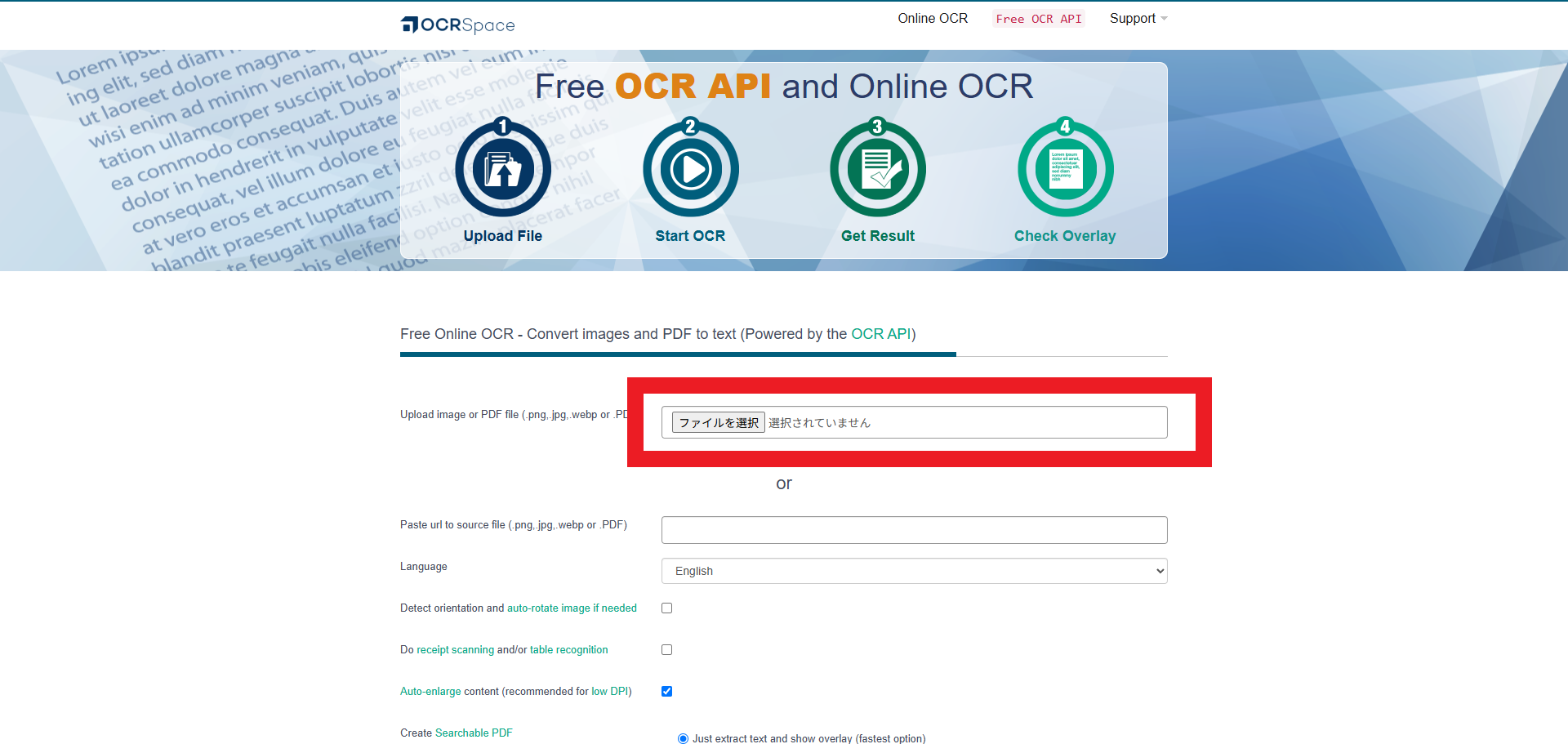
- 「Language(言語)」の項目で日本語(Japanese)を選択します。言語設定を正しく行うことで、日本語の文章も高い精度で認識してくれます。
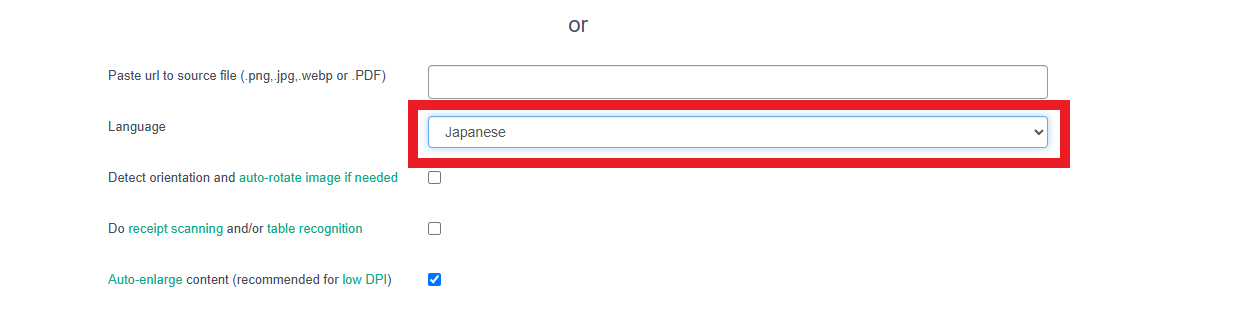
- 「Output(出力形式)」などのオプションで、「Create Searchable PDF(検索可能PDFを作成)」を選びます。この設定により、文字情報を埋め込んだPDFを出力できます(画像と同じ見た目のまま裏にテキストを含むPDFにできます)。
- 準備ができたら「Start OCR!(OCR開始)」ボタンをクリックします。サーバー上でOCR処理が行われるため、処理が完了するまで少し待ちます。

- 処理が終わると、ページ下部にOCR結果のダウンロードリンクが表示されます。「Download」のボタンをクリックして結果を取得しましょう。PDFを選択していた場合は検索可能なPDFがダウンロードされます。開いてテキストを選択できるか確認してみてください。
複数ページをまとめてOCRしたいときは?
紙の書類をスキャンすると、ページごとに別々の画像ファイルになることがあります。そんな時は、OCRの前にそれらの画像を1つのPDFに結合しておくと便利です。例えば、複数画像をまとめてPDF化できる無料サイトの 楽々PDFメーカー(画像→PDF変換機能)を使って一つのPDFファイルにしておけば、先ほどのOCR.Spaceにまとめてアップロードできます。結果も1つのPDFに収まるので、ページごとにファイルを管理する手間が省けます。楽々PDFメーカーは国内開発のオンラインPDFツールで、インストール不要で利用可能です。うまくOCRサービスと組み合わせて活用してみましょう。

方法3: OneNoteなどPCアプリのOCR機能を使う
インターネットに頼らずにPC上でOCRを完結させたい場合は、MicrosoftのOneNoteといったアプリに備わっているOCR機能を使う方法があります。OneNoteはWindowsユーザーであれば無料で利用できるメモ・ノートアプリですが、画像から文字を読み取るOCR機能が密かに搭載されています。Officeが入っていない場合でも、MicrosoftのサイトからOneNote単体をダウンロード可能です。利用手順の一例を見てみましょう。
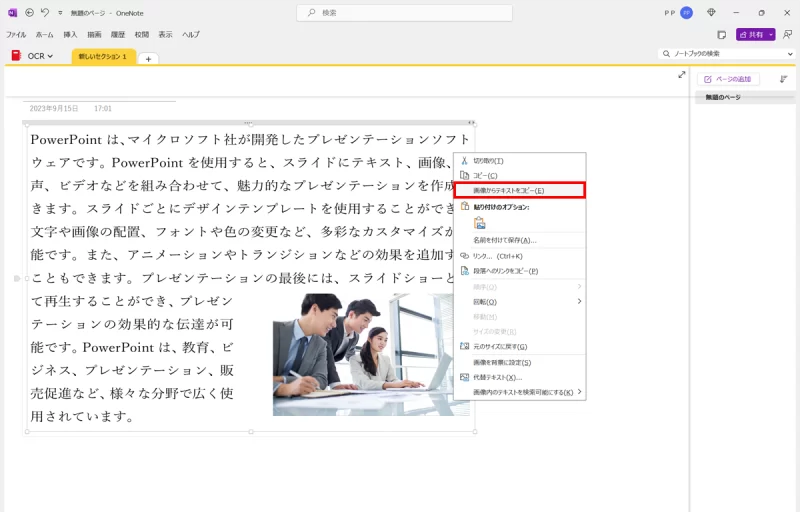
- OneNoteを起動し、新規ノート(ページ)を開きます。初めて使う場合はMicrosoftアカウントでのサインインが必要ですが、ソフト自体は無料で利用できます。
- OCRをかけたい画像ファイルをOneNoteのページ上に挿入または貼り付けします。画像が貼り付くと、そのページ上に画像が表示されます。
- 貼り付けた画像の上で右クリックし、メニューから「画像からテキストをコピー」(またはそれに類する項目)を選択します。すると、OneNoteが画像内の文字解析を行い、テキストをクリップボードにコピーします。日本語のテキストも認識可能です。
- 数秒待った後、メモ帳やWordなど任意のテキスト編集ソフトを開いて貼り付け(ペースト)します。画像の中の文字がテキストデータとして貼り付けられれば成功です。レイアウトは崩れることがありますが、文字情報は取得できます。
- テキストを確認・修正したら、必要に応じてその内容をPDFとして保存します。例えば、Wordに貼り付けて整えた場合は「名前を付けて保存」からPDF形式を選んで保存できます。メモ帳の場合は一度WordやPDFプリンターに渡す必要があります。
方法4: スマホアプリを使ってOCR&PDF化(Adobe Scanなど)
手元にパソコンがなくても、スマートフォンの無料アプリを使って紙の書類を撮影し、OCRでPDF化することもできます。特に便利なのがスキャン専用アプリで、代表的なものに Adobe Scan や Microsoft Lens(旧称 Office Lens)などがあります。これらのアプリは撮影した書類を自動で台形補正して綺麗なスキャン画像にし、さらにOCRで文字を読み取ってPDFとして保存してくれます。使い方の一般的な流れは以下の通りです。

- スマホアプリをインストールします。App StoreやGoogle Playで「Adobe Scan」や「Microsoft Lens」を検索してダウンロードしてください。どちらも基本無料で利用できます。
- アプリを起動し、カメラを使って紙の書類や印刷物を撮影します。アプリが自動的に用紙のサイズや向きを検知し、画像を補正してくれます(ブレないように撮影しましょう)。

- 撮影後、OCR処理が自動実行されます。例えばAdobe Scanでは、スキャン後しばらく待つと「テキストを認識しています…」という表示が出てクラウドOCRが行われ、画像内の文字が解析されます。
- スキャンが完了したら、PDFとして保存します。Adobe Scanでは自動的にPDFファイルがAdobe Document Cloudに保存されますが、共有メニューから端末にエクスポートすることも可能です。Microsoft Lensの場合は保存時に「PDFとして保存」を選択します。
- 保存されたPDFを開いて、文字が検索・選択できるか確認しましょう。正しくOCRされていれば、PDF内の文字を長押ししてコピーしたり、検索機能で単語を探したりできるはずです。
OCRで変換したPDFの活用例
上記の方法で画像から文字を起こし、晴れてテキスト化されたPDFが手に入ったら、ぜひそのPDFを活用してみましょう。最後に、OCR後のPDFの便利な使い方や追加でできることを紹介します。
- キーワード検索で情報整理: OCR済みPDFは文字情報を持っているため、PDFリーダー上でキーワード検索ができます。大量の資料から特定のキーワードを探す際に、一瞬で該当箇所を見つけられるでしょう。紙の資料をめくって探す手間が省け、情報整理がスムーズになります。
- 編集・引用が容易に: テキスト化されたPDFから文字をコピー&ペーストできるので、他の文書への引用や再編集が簡単です。例えばOCR結果を元に報告書を作成したり、必要な部分だけ抜き出してメールに貼り付けたりといったことができます。多少の誤認識があった場合でも、テキスト編集ソフト上で簡単に修正できるのもメリットです。
- PDFの結合や圧縮も活用: 複数のOCR済みPDFを後から1つにまとめたい場合や、不要なページを削除したい場合は、再度 楽々PDFメーカー のPDF結合機能やPDF分割機能が役立ちます。また、スキャンしたPDFは画像を含むためファイルサイズが大きくなりがちですが、PDF圧縮機能を使えば容量を削減して保存・共有しやすくできます。OCRで得たPDFとオンラインPDFツールを組み合わせて使うことで、より一層PDF活用の幅が広がります。
- データの長期保存・活用: テキストデータになったPDFは将来的な資産としても価値があります。社内資料や研究ノートをOCRでPDF化して蓄積しておけば、年月が経ってもデータ検索で目的の情報をすぐ取り出せます。過去の書類を電子アーカイブ化する際にも、OCRによる全文検索可能なPDFは重宝します。
まとめ
画像データから文字起こしをしてPDF化することで、情報の検索性や編集容易性が飛躍的に高まります。無料で使えるOCRツールとして、GoogleドライブのようなクラウドサービスからオンラインOCRサイト、PCソフトやスマホアプリまで多彩な方法があります。
初心者の方でも、本記事で紹介した手順に沿って進めれば簡単にOCRを試せるはずです。まずは手軽な方法からぜひチャレンジしてみてください。紙の書類がデジタルデータとして蘇り、PDF管理がぐっと便利になりますよ。







